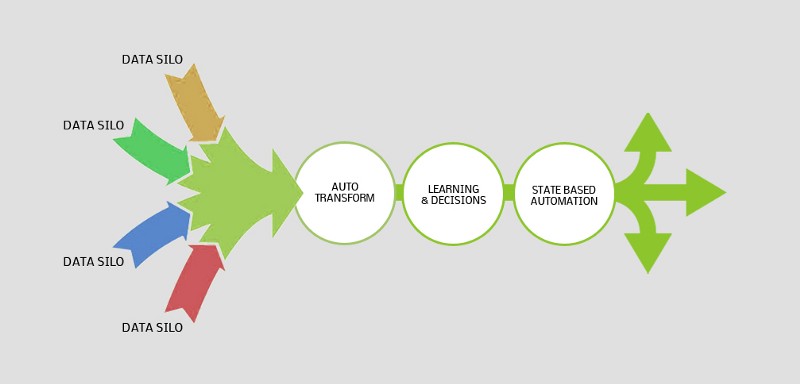

AI is a simple science of being able to decide and carry out functions in real-time just like how human workers do
Just like the way human brain makes decisions, systems that can create a memory of patterns can quickly detect/recognize patterns from past memories, allowing them to make decisions which can be translated to predictive decisions, recommendations or the shortest path to the goal. Based on the status of these states, the system fires the next appropriate function, which could be an engagement with a customer or an insight to a marketer.
This simple mechanism allows the user to observe every step of the learning process, keeping the system transparent and agile. Without transparency, your AI investments could be a very risky proposition
However, implementing AI in your current data ecosystem has its own challenges. Without fixing your data foundation, there is no way to achieve great results with this implementation.
Challenges to Address
Challenges in Data Transformation
As the current environment is in silos, making sense of collective data requires that merging these silos. However, there are some serious challenges in bringing together unstructured and structured data. There is no way that you can transform data from two different sources when they don’t have matching values in both tables. For example, if you were to bring together two customer data sources together like user behavior on website (which has just IP addresses) and app behavior (user email), there is no possibility to a unique IP against a unique email so that you can create a single customer stack
This would mean that a lot of valuable customer information is lost and the available structured set is pushed into the learning model. The outputs of the learning model are as good as the data being provided. Due to incomplete data-sets, the customer pattern is missing and the learning set might not find this pattern at all
To avoid learning errors, it is necessary that the data transformation is complete for the learning foundation to be robust.
Challenges with Data Schema
With more solutions moving towards Schema-on-read approach (data lake), it is evident that there is no plan for the data that gets collected and you start with data collected and add schema to fit your needs. To cater to the needs of a specific challenge, you write a schema that is designed to address this challenge. In this bargain, you write many such schemas.
The regressive part of this approach is that many times you do not fully understand your data and how you will use it. This is especially true for analytics and data mining, where you may have a lot of data that you don’t fully understand yet or don’t all fit the same schema. Instead of creating a schema that fits all, by understanding the data meticulously, businesses implement heuristic solutions where they need to keep changing solutions frequently as business needs evolve and the previously designed heuristic schema has to be reworked, costing the business time and money.
As any business’s fixed primary goal is to achieve profitability for its existence and sustainability, will not change, it is important to design a highly optimized logical schema( logical data model) and the conceptual data model, describing the semantics of an organization without reference to technology.
To arrive at such an optimal logical model where a single data model, isomeric in nature, can restructure itself to solve the different problem areas of a business, we analyzed patterns in different custom schemas to arrive at the most optimal generic schema which is low dimensional. Using the concepts of self-organizing map, we designed a macro data representation of the CDM, to which any logical model could be mapped.
A self-organizing map (SOM) or self-organizing feature map (SOFM) is a type of artificial neural network (ANN) that is trained using unsupervised learning to produce a low-dimensional (typically two-dimensional), discretized representation of the input space, called a map, and is, therefore, a method to do dimensionality reduction. Self-organizing maps differ from other artificial neural networks as they apply competitive learning as opposed to error-correction learning (such s backpropagation with gradient descent), and in the sense that they use a neighborhood function to preserve the topological properties of the input space.
Solving these two main challenges not only creates the right foundation for effective AI implementation, but it is also ready with classification, real-time processing of pattern detection, weight allocation, neighbor detection, predictions and resulting state changes.
Due to lack of the right data foundation, data scientists get access to data-sets that might or might not carry the complete patterns. Which would mean that the training data-set would not encompass all the necessary inputs and data scientists would map whatever is available to the desired output?
For such an approach, data-sets need to contain ample data which is time-consuming and does not help in learning or analyzing in real-time. Customer Engagement requires interacting with customers in real-time by learning past behavior along with the behavior of the current interactions, which would mean that the machine has a memory, understands customer intent, affinity, preferences and every associated parameter and using that information, can communicate contextually and relevantly, creating the same human-like experience.
Solving the above problems, Plumb5’s approach to real-time learning and decision processing is built around building memories of every single customer and their cross-channel interactions to learn and auto-generate probable decisions. These decisions are tightly integrated into the automation layer so machines can fire actions based on decision states instantly, allowing real-time engagement.